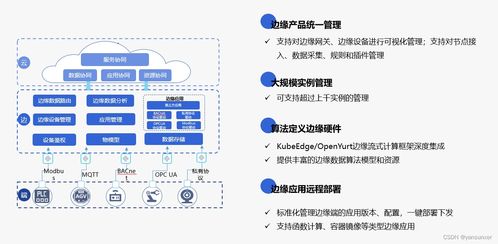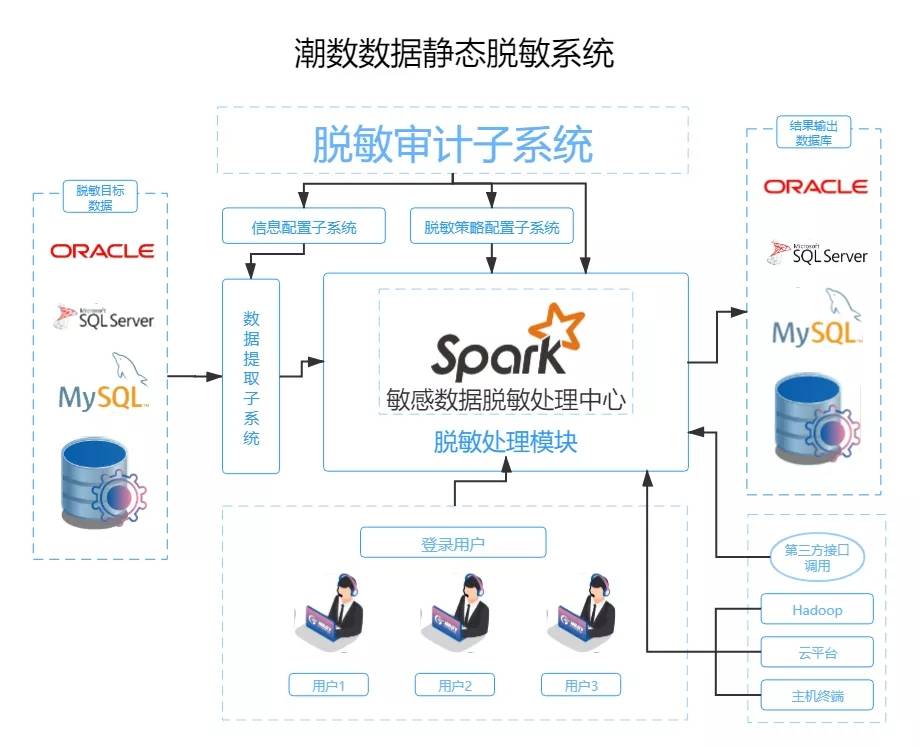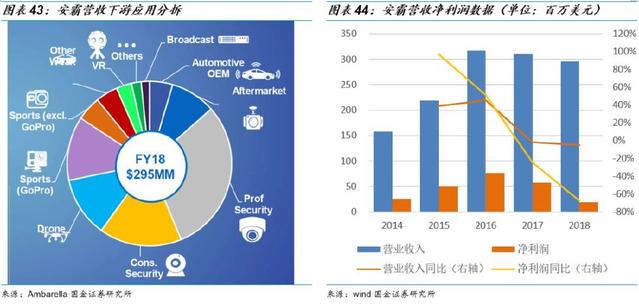
在當今以數(shù)據(jù)驅(qū)動的數(shù)字化時代,構(gòu)建高效、靈活且可擴展的大數(shù)據(jù)技術(shù)架構(gòu)是企業(yè)實現(xiàn)智能化轉(zhuǎn)型的核心基石。本文將系統(tǒng)性地闡述從數(shù)據(jù)中臺到人工智能應(yīng)用的全棧架構(gòu)視圖,并詳細解析其關(guān)鍵組成部分與數(shù)據(jù)處理流程。
一、宏觀架構(gòu)藍圖:從業(yè)務(wù)到技術(shù)
一套完整的大數(shù)據(jù)體系通常呈現(xiàn)為分層架構(gòu),自頂向下貫穿業(yè)務(wù)、產(chǎn)品、平臺與技術(shù)。
- 大數(shù)據(jù)業(yè)務(wù)架構(gòu)圖:這是頂層設(shè)計,定義了數(shù)據(jù)如何賦能業(yè)務(wù)。它明確了數(shù)據(jù)驅(qū)動的業(yè)務(wù)目標、核心應(yīng)用場景(如精準營銷、風險控制、智能運維)以及各業(yè)務(wù)域的數(shù)據(jù)流與價值閉環(huán)。
- 大數(shù)據(jù)產(chǎn)品架構(gòu)圖:在此層面,業(yè)務(wù)需求被轉(zhuǎn)化為具體的數(shù)據(jù)產(chǎn)品與服務(wù)。例如,客戶數(shù)據(jù)平臺(CDP)、數(shù)據(jù)分析平臺、實時推薦引擎等。架構(gòu)圖展示了這些產(chǎn)品的功能模塊、服務(wù)接口及它們?nèi)绾螀f(xié)同滿足用戶(業(yè)務(wù)人員、分析師、開發(fā)者)需求。
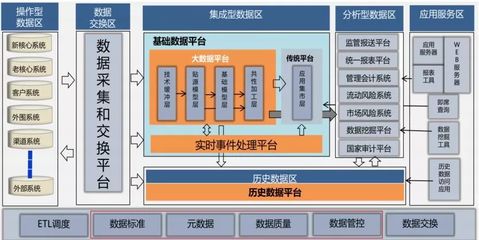
- 數(shù)據(jù)中臺架構(gòu)圖:作為承上啟下的“中樞”,數(shù)據(jù)中臺的核心是統(tǒng)一數(shù)據(jù)資產(chǎn)與能力復用。其架構(gòu)通常包含:
- 數(shù)據(jù)資產(chǎn)層:通過數(shù)據(jù)倉庫(離線)、數(shù)據(jù)湖(原始數(shù)據(jù))和實時數(shù)倉,實現(xiàn)數(shù)據(jù)資產(chǎn)的統(tǒng)一存儲、建模與管理(OneData體系)。
- 數(shù)據(jù)服務(wù)層:將數(shù)據(jù)資產(chǎn)封裝成標準的API、數(shù)據(jù)產(chǎn)品或模型服務(wù)(OneService),供前端業(yè)務(wù)系統(tǒng)便捷調(diào)用。
- 數(shù)據(jù)治理與運營體系:貫穿始終,確保數(shù)據(jù)質(zhì)量、安全、血緣與成本可控。
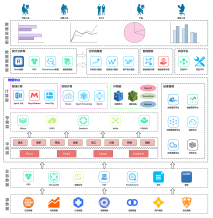
二、技術(shù)實現(xiàn)基石:通用大數(shù)據(jù)技術(shù)架構(gòu)圖
這是支撐以上各層的技術(shù)實現(xiàn)藍圖,一個經(jīng)典的通用大數(shù)據(jù)架構(gòu)圖模版(精品模版) 通常包括以下層次:
- 數(shù)據(jù)采集與接入層:使用Flume、Logstash、Kafka、Sqoop、DataX等工具,實現(xiàn)從數(shù)據(jù)庫、日志、IoT設(shè)備、外部API等多源異構(gòu)數(shù)據(jù)的實時與批量采集。
- 數(shù)據(jù)存儲與計算層:
- 批處理引擎:基于Hadoop HDFS的存儲,配合Hive、Spark進行大規(guī)模離線計算。
- 流處理引擎:采用Flink、Spark Streaming、Kafka Streams處理實時數(shù)據(jù)流。
- OLAP引擎:使用ClickHouse、Doris、Kylin或Presto等,支撐高速交互式查詢與分析。
- NoSQL與檢索:引入HBase、Redis、Elasticsearch滿足特定讀寫與檢索需求。
- 資源管理與調(diào)度層:YARN、Kubernetes等,負責集群資源的統(tǒng)一分配與管理。
- 數(shù)據(jù)開發(fā)與治理層:通過Airflow、DolphinScheduler等調(diào)度工具,以及Atlas、DataHub等元數(shù)據(jù)管理工具,實現(xiàn)任務(wù)編排、數(shù)據(jù)血緣與質(zhì)量管理。
三、核心脈絡(luò):數(shù)據(jù)處理流程圖
數(shù)據(jù)處理流程是架構(gòu)圖中的動態(tài)生命線,清晰地描繪了數(shù)據(jù)從產(chǎn)生到消費的全過程。一個典型的流程包括:
- 數(shù)據(jù)采集與注入:數(shù)據(jù)從源系統(tǒng)被實時或定時抽取、加載至消息隊列或數(shù)據(jù)湖。
- 數(shù)據(jù)預處理與清洗:在計算引擎中進行格式統(tǒng)一、臟數(shù)據(jù)過濾、缺失值處理等ETL(提取、轉(zhuǎn)換、加載)操作。
- 數(shù)據(jù)存儲與分層:遵循維度建模或數(shù)據(jù)湖分層理念(如ODS原始層、DWD明細層、DWS匯總層、ADS應(yīng)用層),將處理后的數(shù)據(jù)存入對應(yīng)存儲。
- 數(shù)據(jù)計算與分析:根據(jù)業(yè)務(wù)需求,進行離線批處理、實時流計算、即席查詢或機器學習訓練。
- 數(shù)據(jù)服務(wù)與消費:計算結(jié)果被推送至數(shù)據(jù)倉庫、可視化報表、API接口或AI模型,最終服務(wù)于決策者、業(yè)務(wù)系統(tǒng)或終端用戶。
四、智能進階:人工智能模版架構(gòu)圖
當大數(shù)據(jù)架構(gòu)需要支撐AI應(yīng)用時,需集成機器學習平臺(MLOps)。該架構(gòu)圖在通用大數(shù)據(jù)架構(gòu)基礎(chǔ)上,擴展出:
- AI基礎(chǔ)設(shè)施層:提供GPU等異構(gòu)計算資源,容器化環(huán)境。
- 數(shù)據(jù)與特征層:強調(diào)特征工程,構(gòu)建統(tǒng)一特征庫,管理訓練與評估數(shù)據(jù)集。
- 模型開發(fā)層:集成Jupyter Notebook、自動化機器學習(AutoML)框架,支持模型實驗、訓練與調(diào)優(yōu)。
- 模型管理與服務(wù)層:使用MLflow等工具進行模型版本管理、注冊;通過高性能服務(wù)框架(如TensorFlow Serving)將模型部署為API。
- 模型監(jiān)控與反饋:監(jiān)控模型線上性能(如預測準確率、延遲),并收集反饋數(shù)據(jù)用于模型迭代,形成閉環(huán)。
一套優(yōu)秀的大數(shù)據(jù)與AI架構(gòu)是一張相互關(guān)聯(lián)、層層遞進的圖譜。它以數(shù)據(jù)中臺為樞紐,以通用大數(shù)據(jù)技術(shù)棧為引擎,通過標準化的數(shù)據(jù)處理流程將原始數(shù)據(jù)轉(zhuǎn)化為燃料,最終驅(qū)動智能業(yè)務(wù)產(chǎn)品的飛輪。企業(yè)可基于此精品模版,結(jié)合自身業(yè)務(wù)特點與技術(shù)棧,繪制出最適合自己的架構(gòu)藍圖,確保數(shù)據(jù)流與價值流的高效運轉(zhuǎn)。